SQL study [21.09.03]
DELETE(/MODIFY) Action
1) CASCADE : Master 삭제시 Child 같이 삭제
2) SET NULL : Master 삭제시 Child 해당 필드는 NULL
3) SET DEFAULT : Master 삭제시 Child 해당 필드는 Default 값으로 설정
4) RESTRICT : Child 테이블에 PK 값이 없는 경우에만 Master 삭제 허용
5) NO ACTION : 참조무결성을 위반하는 삭제/수정 액션을 취하지 않는다.
INSERT Action
1) AUTOMATIC : Master 테이블에 PK 가 없는 경우 Master PK 를 생성 후 Child 입력
2) SET NULL : Master 테이블에 PK 가 없는 경우 Child 외부키를 Null 값으로 처리
3) SET DEFAULT : Master 테이블에 PK 가 없는 경우 Child 외부키를 지정된 기본값으로 입력
4) DEPENDENT : Master 테이블에 PK가 존재할 때만 Child 입력을 허용한다.
5) NO ACTION : 참조무결성을 위반하는 입력 액션을 취하지 않는다.
트랜잭션의 특성 (ACID)
1) 원자성(Atomic) : 트랜잭션에서 정의된 연산들은 모두 성공적으로 실행되던지 아니면 전혀 실행되지 않은 상태로 남아있던지 해야한다.
- 모 아니면 도
2) 일관성(Consistemcy) : 트랜잭션이 실행되기 이전 DB 내용이 문제가 없었다면 트랜잭션이 실행된 이후에도 DB의 내용에 문제가 없어야 한다.
3) 고립성(Isolation) : 트랜잭션이 실행되는 도중 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다.
4) 지속성(Durability) : 트랜잭션이 성공적으로 수행이 되면 그 트랜잭션이 갱신한 DB의 내용은 영구적으로 저장이 된다.
트랜잭션 에서의 문제점
1) Dirty Read : 다른 트랜잭션에 의해 수정이 되었지만, 아직 커밋되지 않은 데이터를 읽는 것
2) Non-Repeatable Read : 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 그 사이 다른 트랜잭션이 값을 수정 또는 삭제하는 바람에 두 쿼리 결과가 다르게 나타나는 현상
3) Phantom Read : 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫번째 쿼리에서 없던 유령 레코드가 두번째 쿼리에서 나타나는 현상
순위함수인 RANK(), DENSE_RANK(), ROW_NUMBER() 정리
2021.09.03 - [Data Base/SQL] - SQL) 순위함수(RANK, DENSE_RANK, ROW_NUMBER)
SQL) 순위함수(RANK, DENSE_RANK, ROW_NUMBER)
순위 함수 RANK(), DENSE_RANK(), ROW_NUMBER() RANK() : 순위에 대해서 중복되는 값들에 대해선 동일한 순위로 표시를 한다. 그리고 다음에 나오는 수의 순위는 이전에 중복되었던 값들의 수만큼 올라간다.
johoonday.tistory.com
NTILE(n)
- n 에 입력이 된 수만큼 data 들을 순위 매긴다. - 학생들이 있는 한 반에서 수학 A반, B반, C 반을 점수로 나누어 수업을 듣게 할 때와 같이 필요한 거 같다.
SELECT Value,
NTILE(3) OVER (ORDER BY Value ASC) AS 'Rank'
FROM Study;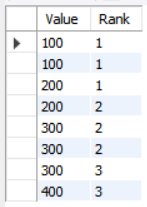
PARTITION BY
- RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE() 은 순위에 따라 데이터가 정렬이 되지만 PARTITION_BY 는 순위는 순위대로 매겨지지만 PARTITION BY 를 통해 특정 속성 별로 구분을 할 수 있다.
CREATE TABLE member (
Name VARCHAR(30),
Class VARCHAR(30),
Score INT
);
INSERT INTO member VALUES
('김덕환', '부장', 920),
('이지연', '과장', 480),
('강길태', '부장', 850),
('박정원', '대리', 300),
('박유리', '대리', 300),
('최고야', '부장', 850),
('남도혁', '과장', 400),
('박미선', '과장', 800),
('이춘재', '부장', 490);
SELECT Name,
Class,
RANK() OVER (PARTITION BY Class ORDER BY Score ASC) AS 'Rank',
Score
FROM member;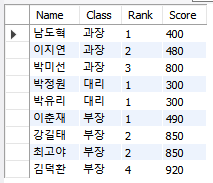
직급으로 분류가 된 테이블이 출력이 되었고, 각 직급마다 점수에 따라 순위가 부여되었다.
WITH <Sub query name> AS ( ... contents ... )
- C++ 언어의 #define 혹은 함수와 같은 존재인 것 같다.
- 위 contents 내부에 구현하고자 하는 서브쿼리를 만든다. SELECT ~ 이런식으로 만들면 된다.
- Classes More Than 5 Students - LeetCode 이 문제를 WITH 를 사용하여 풀어보았다.
WITH courses2 AS (
SELECT DISTINCT *
FROM courses
)
SELECT DISTINCT class
FROM courses2
GROUP BY class
HAVING 4 < COUNT(student);'Data Base > Daily_study' 카테고리의 다른 글
| SQL study [21.09.02] (0) | 2021.09.02 |
|---|---|
| SQL study [21.08.25] (0) | 2021.08.25 |
| SQL study [21.08.24] (0) | 2021.08.24 |
| SQL study [21.08.23] (0) | 2021.08.24 |
| SQL study [21.08.19] (0) | 2021.08.19 |


댓글