트라이 (Trie)
저장된 문자열 탐색에 용이한 자료구조
정의
트라이(Trie) 는 문자열들의 집합이 있을 때 문자열의 존재 여부를 쉽게 찾아낼 수 있도록 해 주는 자료구조 이다. 직관적인 예시를 통해 설명을 해 보았다.
설명
아래 문자열들을 저장 해 보려고 한다.
[저장된 문자열들]
- key
- king
- hi
- hint
- day
- date
위 문자열들은 Trie 자료 구조에서 아래와 같이 저장된다.

만약 'king' 이라는 단어가 저장이 되어 있는지 찾아보고 싶으면 root Node 부터 차례대로 하위 Node로 이동하여 'k', 'i', 'n', 'g' 를 찾아가면 된다. 만약 저 자료구조에는 존재하지 않는 'keep' 이라는 단어를 찾아보려 한다면,
root Node ⇒ 'k' Node ⇒ 'e' Node ⇒ 'e'Node 존재 X
위와 같은 과정을 통해 'keep'이라는 단어가 존재하지 않는 것을 확인할 수 있다.
여기서 저 자료구조만 보고 존재하는지 안 하는지 애매한 단어가 있다. 바로 'hi' 이다. 'hi' 에 추가적인 문자들이 더 붙은 다른 'hint' 라는 단어가 있기 때문에 결국 묻혀버리게(?) 되었다. 이러한 상황을 대비하기 위해 각 Node 들에는 해당 Node 가 어떠한 단어의 끝에 해당되는 Node 인지 아닌지 여부를 판단하는 옵션이 있어야 한다.
class Node {
public:
// ...
bool isEnd;
// ...
}위와 같은 옵션을 통해, h 로 시작하는 두 단어는 자료 구조에서 아래와 같이 저장이 된다.

지금 까지는 Trie 자료 구조에 저장이 된 형태를 보았고, 해당 단어가 삽입되는 과정을 순서대로 표현 해 보았다.
[저장될 문자열들의 순서]
- key
- hi
- king
- hint

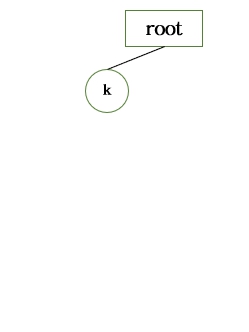
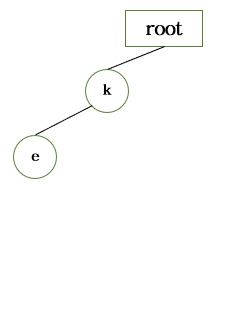






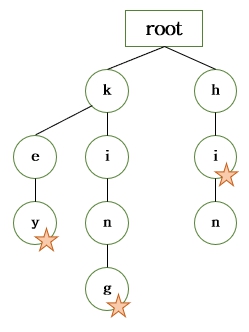

옆에 ★ 표시가 있는 Node 는 단어의 끝에 해당되는 Node 들 이다.
<정리>
1. 트라이(Trie) 자료 구조는 문자열의 탐색이 용이한 자료구조 이다.
2. 각 Node마다 단어의 끝을 알리는 변수가 필요하다.
Code
#include <vector>
#include <string>
using namespace std;
int n;
class Node {
public:
Node* child[26];
bool isEnd;
Node() : isEnd(false) {
for (int i = 0; i < 26; i++)
child[i] = NULL;
}
};
class Tri {
public:
Node* root = new Node;
int cntSum;
Tri() : cntSum(0) {};
~Tri() {
Delete(root);
}
void push(string& str) {
insert(str, 0, root);
}
private:
void insert(string& str, int index, Node* curNode) {
if (str.length() == index) {
curNode->isEnd = true;
return;
}
char nextWord = str[index];
if (curNode->child[nextWord - 'a'] == NULL)
curNode->child[nextWord - 'a'] = new Node;
insert(str, index + 1, curNode->child[nextWord - 'a']);
}
void Delete(Node* curNode) {
for (int i = 0; i < 26; i++)
if (curNode->child[i] != NULL)
Delete(curNode->child[i]);
delete curNode;
}
};관련 문제
아래 게시한 트라이(Trie) 관련 문제들을 통해 더 잘 알아갈 수 있다.
// 링크 준비중
댓글